Excel(エクセル)で指数分布の確率の計算をする時には『EXPON.DIST』と『EXPONDIST』関数を使うと計算が可能になっているんですね。ちなみに関数の読み方は『エクスポーネンシャル・ディストリビューション(EXPON.DIST・EXPONDIST)』となります。どちらも同じ読み方ですね。これらを活用する事により、指数分布の確率の計算出来る訳ですがどんな計算なんでしょうか?【指数分布?】ってなっている方も多いと思いますので、今回は指数分布の確率の例と関数の活用方法、計算結果の例について紹介します。
【EXPON.DIST】【EXPONDIST】関数の説明動画はこちら↓↓
目次
【EXPON.DIST】と【EXPONDIST】関数で指数分布の確率を計算してみよう!
今回のExcel関数を活用した指数分布の確率計算をやってみましょう。
計算をするにあたり、解っておかないといけない事がありますね。それは
- 指数分布の確率って何か?
- 『EXPON.DIST』と『EXPONDIST』の異なっている部分が何か?
と言った感じの所になりますね。まずはこの2つを確認して関数の活用をしてみましょう
【EXPON.DIST】と【EXPONDIST】で計算出来る指数分布の確率って何?
さて、これらの関数で求められる指数分布の確率について理解をして行きましょう!
指数分布の確率は、連続して起きる事象に対して、期間を決めた時にその事象が起こる確率という感じになります。関数の説明動画で話している例で言えば、毎月平均20人の新規顧客の来訪がある企業で、今月の新規の顧客が来るタイミングとして、何日目に来る確率が高いのかというのが求められます。
月に20人ですから4日目に来るかもしれないとか10日目になるかもしれないとかの確率が分かる訳ですね。
分布の確率としては、ベルヌーイ試行に対する度数分布の確率や、ガンマ分布の確率というのもやりましたね。それぞれの分布の確率の違いに気を付けて使い分けて行きましょう!
Excelの指数分布の関数【EXPON.DIST】と【EXPONDIST】の違いって何?
Excelには、指数分布の確率を計算するこの2つの関数が準備されていますが、今回テーマの2関数『EXPON.DIST』と『EXPONDIST』の異なる部分というのはあるででしょうか?
答えは関数の計算内容に違いはないです。
これらはエクセルのバージョンアップの際に関数が増えた物になっています。ドットがついている『EXPON.DIST』の方が新しく後から出来上がった物になっている訳ですが、引数や計算結果に違いはありません。今の所はどちらを活用してもいいですが、古い方はいつ無くなるか分からないので、これから活用したいという場合は新しい方を使用する事をおすすめします。
関数を活用する為の引数をおさえよう!
『EXPON.DIST』関数と『EXPONDIST』についてどのような引数になるのか確認をしてみよう。
関数式:『=EXPONDIST(x、λ、関数形式)』
関数式:『=EXPON.DIST(x、λ、関数形式)』
- 指数分布の確率を計算します
- 関数形式では『TRUE』か『FALSE』を指定します。
- 『TRUE』の場合は累積分布関数、『FALSE』は確率質量関数という事になります。
引数の内容としてもどちらも一緒になりますね。
1か月間でλ人来るお店でx日までに新規でお客さんがくる確率が分かります。関数形式については『TRUE』か『FALSE』を指定します。
『FALSE』の時はx日に新規の人が来る確率という考え方で、『TRUE』の場合はx日までに新規の人が来る確率という違いになります。何を求めたいのかで使い分けましょう!
指数分布の確率を関数の計算でやってみよう!
関数により指数分布の計算をやってみますが、『EXPON.DIST』関数と『EXPONDIST』は同じなので、新しい方を活用して、計算してみる事にします。
上記の例で出した通り、毎月平均20人の新規顧客の来訪がある企業で、今月の新規の顧客が来るタイミングが何日目に来るのかの確率を出してみます。
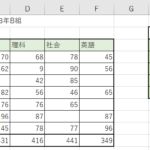
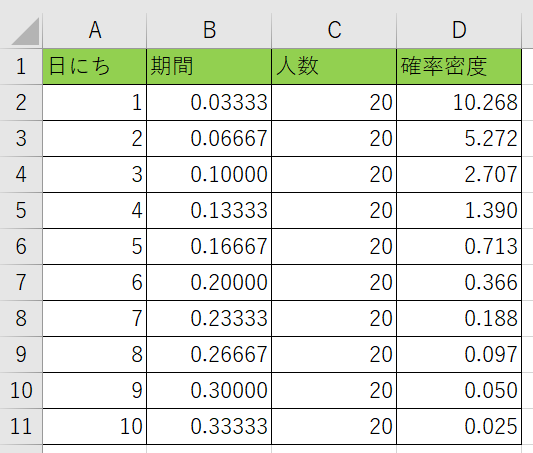
表を準備しました。内容としてはA列には分かりやすい様に日にちを入れています。計算ではこの数値は使用しません。B列が計算で使う日にちになります。内容的には今回は1か月を30日として考え、1か月の中の1日目であれば『1/30(30分の1)』の数値を指定します。C列が1か月に来る新規の人数になります。
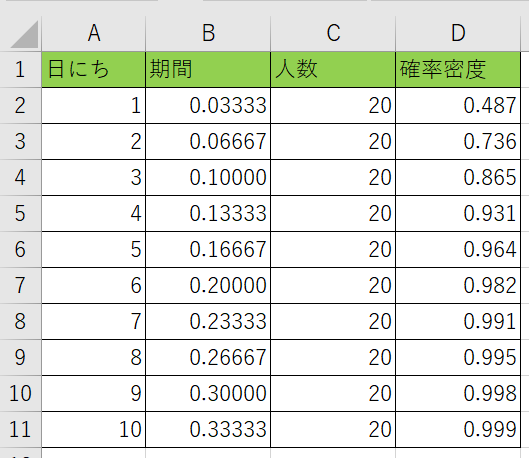
関数形式TRUEの場合
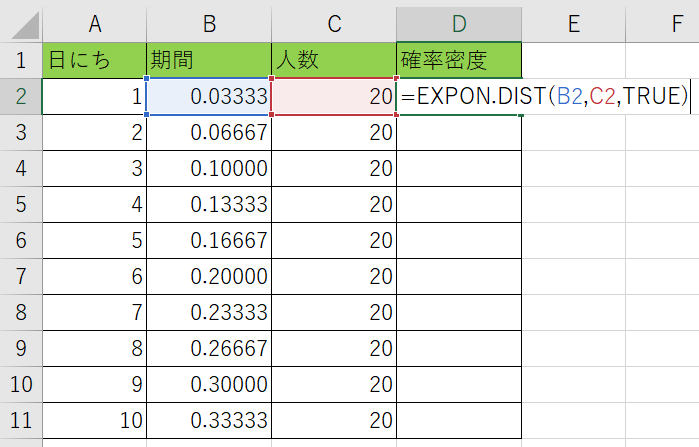
D列に『=EXP.DIST(B2、C2、TRUE)』と記入をする訳ですね。
コピーして表を埋めてみると、どのどのタイミングまでで新規の人が来るのか分かりますね。
今回だと2日目で78%くらいの割合でくるみたいですね。
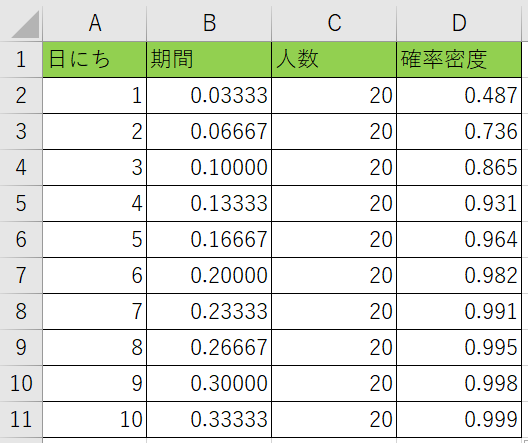
関数形式FALSEの場合
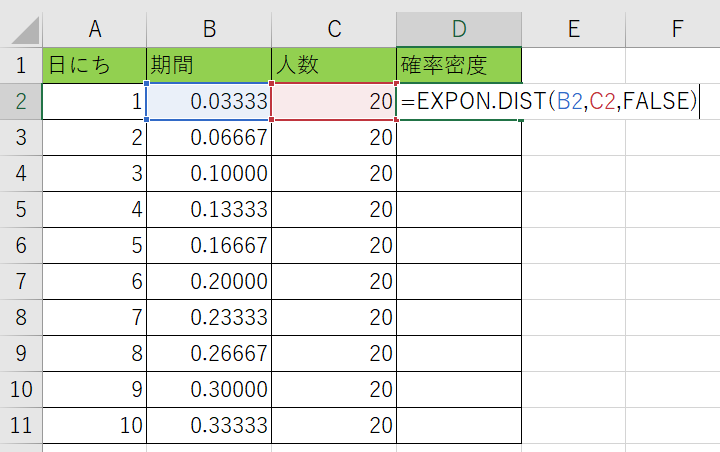
D列に『=EXP.DIST(B2、C2、FALSE)』と記入をする訳ですね。
コピーして表を埋めてみると、どのどのタイミングで新規の人が来るのか分かりますね。
今回だと1日目に来る時の数値が一番高いので、初日に来るかもしれませんね。
ちなみに数値は%では無いので気を付けましょう。
Excelで指数分布の確率を【EXPON.DIST】【EXPONDIST】関数で計算しよう|【まとめ】
Excel(エクセル)の関数『EXPON.DIST』と『EXPONDIST』を活用した指数分布の確率について紹介しました。指数分布がどんな時に使っているのかという所が1つのポイントでしたよね。
今回は新規顧客の来るタイミングという感じで求めてみましたが、これは引き続き起こりうるであろう事象に対してであれば計算可能なものとなっているので、これまでの期間の平均から、ある期間において結果がどうなるのかという感じで計算出来ると良いですね。
様々な分布の計算がありましたが、エクセルの関数には『EXPON.DIST』・『EXPONDIST』関数と言った感じで、それぞれの分布に合わせた関数が準備されています。
違いを理解して、分析が出来る様にして使い分けて活用して行きましょう!